Efficient Autoregressive Audio Modeling via Next-Scale Prediction
TL;DR: We build a Scale-level Audio Tokenizer and Scale-based Acoustic AutoRegressive Modeling for generation based on acoustic prompts.
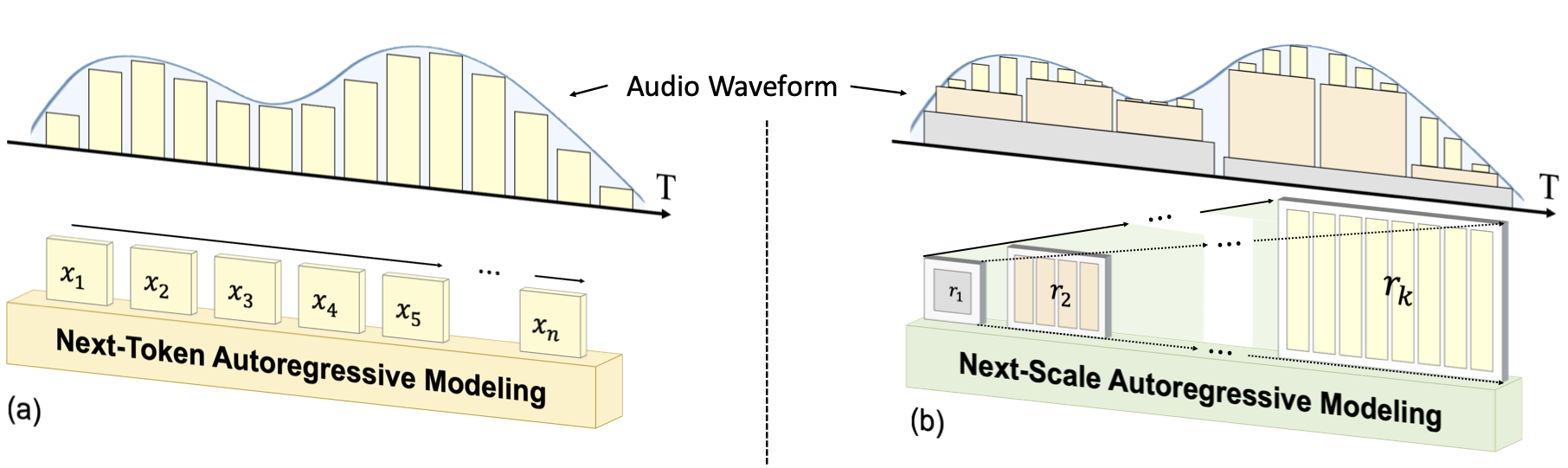
Audio generation has achieved remarkable progress with the advancement of sophisticated generative models, such as diffusion models (DMs) and autoregressive (AR) models. However, due to the naturally long sequence length of audio, the efficiency of audio generation remains a significant challenge, particularly for AR models integrated into large language models (LLMs). In this paper, we analyze the token length of audio tokenization and propose a novel Scale-level Audio Tokenizer (SAT) with enhanced residual quantization. Building on SAT, we introduce a scale-level Acoustic AutoRegressive (AAR) modeling framework, which shifts the AR prediction from the next token to the next scale, significantly reducing both training cost and inference time. To validate the effectiveness of the proposed approach, we conduct a comprehensive analysis of design choices and demonstrate that the AAR framework achieves a remarkable 35× faster inference speed and an improvement of +1.33 in Fréchet Audio Distance (FAD) over baselines on the AudioSet benchmark.
Overall Quality:
Source
Source
Source
Reconstructed with scale (quanlity increasing with scale increasing) :
Scale 1
Scale 1
Scale 1
Scale 5
Scale 5
Scale 5
Scale 9
Scale 9
Scale 9
Scale 13
Scale 13
Scale 13
Generation given by AudioSet eval acoustic embedding:
human singing
hand drum
string instruments
human talk
piano
drumbeat
@misc{qiu2024efficient,
title={Efficient Autoregressive Audio Modeling via Next-Scale Prediction},
author={Kai Qiu and Xiang Li and Hao Chen and Jie Sun and Jinglu Wang and Zhe Lin and Marios Savvides and Bhiksha Raj},
year={2024},
eprint={2408.09027},
archivePrefix={arXiv},
primaryClass={cs.SD}
}